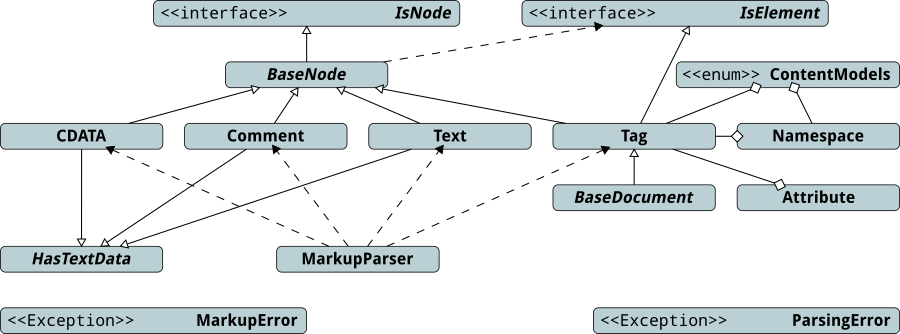
With two interfaces and one abstract class done, there's one more abstract
class that needs attention before I can get to some concrete implementation
(finally): the HasTextData abstract class.
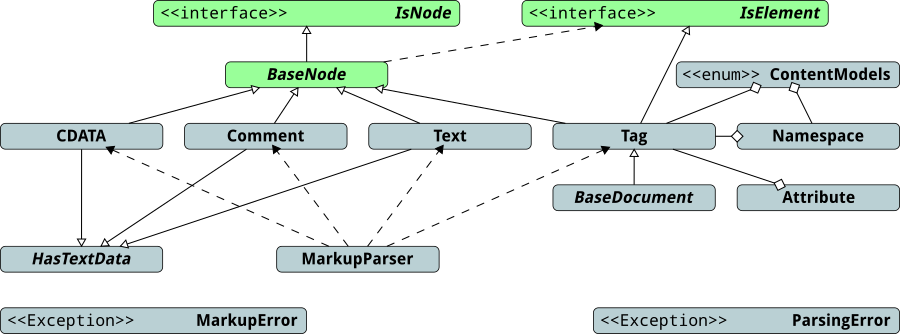
HasTextData is a common super-class for the CDATA,
Comment and Text concrete classes, and completion
of those three classes is my goal for today's post.
What's Common Between These Classes?
Any time there's an abstract class that multiple concrete classes derive from,
there's some common basis of functionality that the concrete classes share. That
is, after all, one of the reasons that an abstract class gets defined. In the case
of HasTextData, that commonality is that all of the derived classes
have a text-data property (data in JavaScript, though the
textContent property will also return that inner text in JavaScript).
Another common factor, though it may be less obvious, is that all three of these
node-types have some rules about what their data can
contain. Those rules aren't necessarily active in a client-side
JavaScript implementation (likely because some sort of action is taken to prevent
destructive or counterproductive content-manipulation — like setting the
inner text of a comment to
). Since the markup being
created has to be issued out to a client browser in some fashion after it's been
created and/or altered on the server side, though, there is a need to enforce at
least some basic content-protection or escaping for all three of those concrete
classes, though the specifics of what they are or do will probably vary
pretty significantly.
-->
All three of those concrete classes also have to be able to be
rendered in some fashion and returned to the client browser as text-data. It could
be str- or unicode-typed text, and should probably
support both on basic principle, but somewhere along the line whatever any
individual instances exist as part of a response, they should contribute
something to the source-code of the response. I'll dig in to the rendering
aspects of all nodes later on in this post — first, some actual
implementation!
The HasTextData Abstract Class
Because, once again, the JavaScript entities that I'm trying to stay consistent
with allow more than one property or method entry-point into the underlying data
— in this case, both data and textContent
properties being capable of getting, setting, or deleting the text-data of a
comment- or text-node — I don't have any better option than to have multiple
properties defined that allow the same capability.
#-----------------------------------#
# Instance Properties (abstract OR #
# concrete!) #
#-----------------------------------#
data = describe.makeProperty(
_GetTextData, _SetTextData, _DelTextData,
'the raw text-data of the instance',
str, unicode
)
textContent = describe.makeProperty(
_GetTextData, _SetTextData, _DelTextData,
'the raw text-data of the instance',
str, unicode
)_SetTextData setter-method:
@describe.AttachDocumentation()
@describe.argument( 'value',
'the raw text data to set in the instance',
str, unicode
)
@describe.raises( TypeError,
'if a value is passed that is not a str or unicode type'
)
# self._SanitizeInput can raise ValueError
@describe.raises( ValueError,
'if a value is passed that cannot be sanitized by the '
'instance to make rendering safely viable'
)
def _SetTextData( self, value ):
"""
Gets the raw text-data of the instance"""
if type( value ) not in ( str, unicode ):
raise TypeError( '%s.TextData expects a str or '
'unicode value, but was passed "%s" (%s)' % (
self.__class__.__name__,
value, type( value ).__name__
)
)
# Make sure that the supplied raw text-data is safe to
# store before storing it.
value = self._SanitizeInput( value )
self._textData = valuesanitizethe supplied input, with the intention being that the sanitized input will alter anything that could result in rendering issues on the client side. The specifics of the sanitization will vary at least a little bit in the concrete class implementations, so
_SanitizeInput is abstracted in HasTextData:
@abc.abstractmethod
@describe.raises( ValueError,
'if a value is passed that cannot be sanitized by the '
'instance to make rendering safely viable'
)
def _SanitizeInput( self, value ):
raise NotImplementedError( '%s._SanitizeInput is not implemented as '
'required by HasTextData' % self.__class__.__name__ )Rendering Considerations
All of the concrete classes, not just CDATA, Comment
and Text, will eventually need to be able to be rendered and
returned as part of a web request-response cycle. As things stand right now,
having done some cursory examination of both mod_python and
wsgi response-functionality, I'm inclined to handle that by using
the __str__
and/or __unicode__
magic methods
that are available to all Python objects.
The main rationale for this is that both mod_python and basic
wsgi response-functionality, ultimately, just need to return the
text of a response. The specific mechanisms how that response
is returned may vary, maybe even vary a lot, but that returning-some-text
is the key.
That more or less requires that __str__ and __unicode__
be defined as abstract methods somewhere in the class-hierarchy. Since
they should be available to all nodes (and because it'd keep that functional
requirement in a single place), I'm going to add them all the way back up in
IsNode:
@abc.abstractmethod
def __str__( self ):
raise NotImplementedError( '%s.__str__ is not implemented as '
'required by IsNode' % self.__class__.__name__ )
@abc.abstractmethod
def __unicode__( self ):
raise NotImplementedError( '%s.__unicode__ is not implemented as '
'required by IsNode' % self.__class__.__name__ )Unit-testing HasTextData
Of the required test-methods for HasTextData, only one can
really be implemented at this point: test_SanitizeInput, following
the usual structure for testing that an abstract member is abstract in the class.
The rest, all of the property-methods, would all rely on a concrete implementation
of _SanitizeInput. There are a couple of different approaches that could be taken at this point to resolve this conundrum:
- Skip the tests in
testHasTextDataand make sure that the derived-class tests test them adequately; or - Create a
HasTextData-derived test-class that has a concrete implementation of_SanitizeInput, then test against that test-class.
Setting up a test-class is simple in this case:
class HasTextDataDerived( HasTextData ):
def __init__( self ):
HasTextData.__init__( self )
def _SanitizeInput( self, value ):
return '[Sanitized] %s' % value_SanitizeInput of the test-class, it actually needs
to alter the value submitted, hence the [Sanitized]Since the data and textContent properties should
both use the same getter-, setter- and deleter-methods, only one of the test-methods
between the two required for those properties actually needs to check the functionality.
The other one can be tested by asserting that the underlying methods are
identical:
def testdata(self):
"""Unit-tests the data property of a HasTextData instance."""
testObject = HasTextDataDerived()
# test default state
self.assertEquals( testObject.data, '',
'The default data value for a newly-created instance should '
'be an empty string' )
# Test setting then getting all "good" values
for testValue in UnitTestValuePolicy.Text:
testObject.data = testValue
expected = '[Sanitized] %s' % testValue
actual = testObject.data
self.assertEquals( actual, expected,
'instance.data should equal %s if it was set to %s, '
'but %s was returned instead' % (
expected, testValue, actual
)
)
# Test setting all "bad" values and keeping the previous state
testObject.data = 'original value'
expected = testObject.data
for testValue in (
UnitTestValuePolicy.Numeric +
UnitTestValuePolicy.Boolean.Strict + [ object() ] ):
try:
testObject.data = testValue
self.fail( 'Setting instance.data to a non-string value '
'("%s" [%s]) should raise a TypeError' % (
testValue, type( testValue ).__name__
)
)
except TypeError:
self.assertEquals( testObject.data, expected,
'Failure to set instance.data should have left it '
'set to "%s", but it was re-set to "%s"' %
( expected, testObject.data )
)
def testtextContent(self):
"""Unit-tests the textContent property of a HasTextData instance."""
self.assertEquals(
HasTextData.textContent.fget, HasTextData.data.fget,
'HasTextData.textContent and HasTextData.data '
'are expected to use the same property-getter method'
)
self.assertEquals(
HasTextData.textContent.fset, HasTextData.data.fset,
'HasTextData.textContent and HasTextData.data '
'are expected to use the same property-setter method'
)
self.assertEquals(
HasTextData.textContent.fdel, HasTextData.data.fdel,
'HasTextData.textContent and HasTextData.data '
'are expected to use the same property-deleter method'
)UnitTestValuePolicy
constant, defined about
a month ago, to use.
With those property-tests in place and passing, the question arises of whether
there's any useful testing that can be done of the underlying methods
of the properties. This was one of the items that came up when I posted the
Unit-Testing
Walk-through a couple of weeks back, that I didn't want to get too far
into the weeds
about at the time, but it's probably a good time to
address it in some detail now that there's a more detailed example to look at
for context.
In general, and in keeping with the thoroughly tested
goal in my
coding standards,
the unit-testing policy requires that test-methods be defined for all
public and protected members. The implication, I hope, is that all the required
test-methods should also be implemented — otherwise why have
the requirement for their definition. That may well break down in the case of
properties and their underlying methods, though. Consider the testdata
test-method above. It:
- Calls the
_DelTextDataproperty-deleter method (at least indirectly, during initialization of theHasTextDataDerivedtest-class, which callsHasTextData.__init__, which callsself._DelTextData); - Calls
_SetTextDataduring every property-value assignment; and - Calls
_GetTextDataduring every property-value retrieval.
goodvalues (that should not raise errors) and
badvalues (that should), every path through every underlying property-method has been executed and shown to behave as expected. Since that is the goal of unit-testing, it follows that the test-methods for the property-methods aren't really needed if the properties that use them test completely and successfully.
I'd rather not try to work out a way to automatically skip, or otherwise remove property-methods from required test-methods, though. Even if it were possible to determine the relationship (my initial tests against that idea lead me to think it's not), doing so feels... fragile, maybe? Although I can't think of a case where I'd expect to need separate tests for the property-methods, I can't rule out that such cases could exist (at least not yet).
Taking all of that together, I think this is sufficient justification for skipping the test-methods of the underlying property-methods, so long as the reason for skipping them is noted:
@unittest.skip( 'Adequately tested by the testdata method' )
def test_DelTextData(self):
"""Unit-tests the _DelTextData method of a HasTextData instance."""
self.fail( 'test_DelTextData is not implemented' )
@unittest.skip( 'Adequately tested by the testdata method' )
def test_GetTextData(self):
"""Unit-tests the _GetTextData method of a HasTextData instance."""
self.fail( 'test_GetTextData is not implemented' )
@unittest.skip( 'Adequately tested by the testdata method' )
def test_SetTextData(self):
"""Unit-tests the _SetTextData method of a HasTextData instance."""
self.fail( 'test_SetTextData is not implemented' )######################################## Unit-test results ######################################## Tests were successful ... False Number of tests run ..... 67 + Tests ran in ......... 0.01 seconds Number of errors ........ 0 Number of failures ...... 15 ########################################
Implementing CDATA, Comment and
Text Classes
Since I don't have a complete class-diagram (with all of the members of the
items I've defined so far), I started by creating stub-classes for CDATA,
Comment and Text, then created a test-case for one
of them (I picked testCDATA) to get a list of all of the members
that will need to be defined for all three concrete classes. The test-case
returned:
TypeError: Can't instantiate abstract class CDATA with
abstract methods
_SanitizeInput, __str__, __unicode__, cloneNode,
isEqualNode, nodeName, nodeType, textContent,
toString
Since all three of these concrete classes derive from BaseNode and
HasTextData, this list should hold true for all of them, at least
as a starting-point.
Or it would, except that I noticed that textContent
was appearing in the list. And I just got finished implementing
textContent in HasTextData! As it turns out, the reason this happened was pretty simple, I'd just forgotten some of the rules about Python's MRO. To explain, let me start by showing the original definition of CDATA I had:
@describe.InitClass()
class CDATA( BaseNode, HasTextData, object ):
"""
Represents a CDATA section in a markup tree"""
# ...BaseNode and HasTextData both define the textContent
property of an instance — one (BaseNode) as an abstract
property requirement that it inherits from IsNode, the other
(HasTextData) as a concrete property that, in theory,
should be fulfilling that interface contract. The problem is that when Python
reads super-classes, they are handled last-to-first, so that BaseNode.textContent
ends up overriding HasTextData.textContent. This can be shown by
switching the order of those super-classes...
@describe.InitClass()
class CDATA( HasTextData, BaseNode, object ):
"""
Represents a CDATA section in a markup tree"""
# ...TypeError: Can't instantiate abstract class CDATA with
abstract methods
_SanitizeInput, __str__, __unicode__, cloneNode,
isEqualNode, nodeName, nodeType, toString
With that change, textContent no longer appears in the list of abstract
members that need to be implemented in the concrete class.
If I haven't mentioned it before, I'll say it now: One of the reasons that I like Python is that it allows multiple inheritance. That makes a lot of class-structure design cleaner, I think, since it's possible to keep all functionality relating to a single aspect of multiple classes' functionality in a single place in the code. That usually eliminates, but at a minimum reduces the likelihood of needing and implementing duplicate code across multiple classes. There are some trade-offs that arise, though, and this sort of inheritance-order dependency is an example of one of them — the code becomes more sensitive to the specific order of inheritance. There are a at least two different ways this could be dealt with.
The first is the simple reversal that I already showed. The caveat with that
approach is that the class-definitions are a bit more fragile — particularly
if yet another class gets added into the mix for any of the concrete
classes. That's a minimal risk at this point, though, I thnk — while there
are two places that textContent is defined, and there may be other
properties that will have similar duplicated definitions, I don't expect that there
are any more that have the kind of combination that textContent has:
and abstract requirement and a concrete implementation originating from different
places in the inheritance tree.
The other would be to change the ineritance-tree. Right now the problem is
that BaseNode (with its IsNode parent) lives in a
completely separate branch of the tree than HasTextData does. If
HasTextData were moved so that it's derived from
BaseNode, then the textContent of BaseNode
would be overridden by HasTextData:

dummymethods (all the ones that didn't exist as requirements before) in the
HasTextDataDerived
derived class in test_markup, but those don't need to be anything
more complex than:
class HasTextDataDerived( HasTextData ):
def __init__( self ):
HasTextData.__init__( self )
def _SanitizeInput( self, value ):
return '[Sanitized] %s' % value
def __str__( self ):
pass
def __unicode__( self ):
pass
def cloneNode( self ):
pass
def isEqualNode( self ):
pass
def nodeName( self ):
pass
def nodeType( self ):
pass
def toString( self ):
passSome Commonalities in these Classes
Looking at the list of dummy
methods above, it occured to me that most
of the methods listed there, all of them from cloneNode on, could
be moved to HasTextData as concrete implementations.
The cloneNode method really doesn't need to do anything more
than create and return a new instance of the class, populated with the
data of the instance being cloned. That can be done with something
pretty simple:
@describe.AttachDocumentation()
@describe.argument( 'deep',
'indicates whether to make a "deep" copy (True) or '
'not (False); irrelevant for HasTextData nodes',
bool
)
@describe.returns( 'a new instance of the class, populated '
'with the data of the current instance' )
def cloneNode( self, deep=False ):
"""
Clones the instance."""
return self.__class__( self._textData )def testcloneNode(self):
"""Unit-tests the cloneNode method of a HasTextData instance."""
# Test instances using all "good" values
for testValue in UnitTestValuePolicy.Text:
instance1 = HasTextDataDerived( testValue )
instance2 = instance1.cloneNode()
self.assertEquals( instance1.__class__, instance2.__class__,
'cloneNode should return the same type of object, '
'but instance2 was a %s, not a %s' % (
instance2.__class__.__name__,
instance1.__class__.__name__
)
)
self.assertEquals( instance1.data, instance2.data,
'an instance returned by cloneNode should have the same data '
'as the original instance, but the cloned instance had "%s" '
'instead of "%s"' % ( instance2.data, instance1.data )
)isEqualNode is similarly simple:
@describe.AttachDocumentation()
@describe.argument( 'deep',
'indicates whether to make a "deep" copy (True) or '
'not (False); irrelevant for HasTextData nodes',
bool
)
@describe.returns( 'True if the other node is the same type and '
'has the same data as the instance, False otherwise.' )
def isEqualNode( self, other ):
"""
Compares the instance against another item."""
return (
self.__class__ == other.__class__
and self.data == other.data
)isEqualNode
from the w3schools
site moot — If the instance and the other object are of
the same type, they'll have all of the same values common to any instance
of the class, so there's no need to do anything more than compare the classes of
self and other and the data values of
them. The test-method requires the creation of another class derived from HasTextData,
but it's pretty much a carbon copy of the original derived test-class
(HasTextDataDerived), and is also very simple:
def testisEqualNode( self ):
"""Unit-tests the isEqualNode method of a HasTextData instance."""
# Test instances using all "good" values
for testValue in UnitTestValuePolicy.Text:
instance1 = HasTextDataDerived( testValue )
# same class, same content
instance2 = HasTextDataDerived( testValue )
self.assertTrue( instance1.isEqualNode( instance2 ),
'Same class and same content should return isEqualNode '
'of True' )
# different class, same content
instance2 = HasTextDataDerived2( testValue )
self.assertFalse( instance1.isEqualNode( instance2 ),
'Different class and same content should return isEqualNode '
'of False' )
# same class, different content
instance2 = HasTextDataDerived( 'other content' )
self.assertFalse( instance1.isEqualNode( instance2 ),
'Same class and different content should return isEqualNode '
'of False' )
# different class and different content
instance2 = HasTextDataDerived2( 'other content' )
self.assertFalse( instance1.isEqualNode( instance2 ),
'Different class and different content should return '
'isEqualNode of False' )The nodeName and nodeType propeties can be
defined to return a class-level attribute that is defined as None in HasTextData,
and that will set to a different value in the concrete classes:
#-----------------------------------#
# Class attributes (and instance- #
# attribute default values) #
#-----------------------------------#
_nodeName = None
_nodeType = None
#-----------------------------------#
# Instance property-getter methods #
#-----------------------------------#
@describe.AttachDocumentation()
def _GetnodeName( self ):
"""
Gets the (class-constant) name of the node"""
try:
result = self.__class__._nodeName
if result == None:
raise AttributeError()
except AttributeError:
raise AttributeError( '%s does not have a class-level '
'definition of _nodeName, or it is inheriting the None '
'value defined by HasTextData' % (
self.__class__.__name__
)
)
return result
@describe.AttachDocumentation()
def _GetnodeType( self ):
"""
Gets the (class-constant) type of the node"""
try:
result = self.__class__._nodeType
if result == None:
raise AttributeError()
except AttributeError:
raise AttributeError( '%s does not have a class-level '
'definition of _nodeType, or it is inheriting the None '
'value defined by HasTextData' % (
self.__class__.__name__
)
)
return result
# ...
#-----------------------------------#
# Instance Properties (abstract OR #
# concrete!) #
#-----------------------------------#
nodeName = describe.makeProperty(
_GetnodeName, None, None,
'the (class-constant) name of the node',
str, unicode
)
nodeType = describe.makeProperty(
_GetnodeType, None, None,
'the (class-constant) type of the node',
str, unicode
)def testnodeName(self):
"""Unit-tests the nodeName property of a HasTextData instance."""
instance = HasTextDataDerived()
actual = instance.nodeName
expected = HasTextDataDerived._nodeName
self.assertEquals( actual, expected,
'An instance of HasTextData with a defined _nodeName '
'should return that value in its nodeName proeprty, but '
'"%s" (%s) was returned instead' % (
actual, type( actual ).__name__
)
)
instance = HasTextDataDerived2()
try:
actual = instance.nodeName
expected = HasTextDataDerived._nodeName
self.fail( 'An instance of HasTextData that does not have '
'a _nodeName class-propery defined should raise an '
'AttributeError if nodeName is retrieved' )
except AttributeError:
pass
def testnodeType(self):
"""Unit-tests the nodeType property of a HasTextData instance."""
instance = HasTextDataDerived()
actual = instance.nodeType
expected = HasTextDataDerived._nodeType
self.assertEquals( actual, expected,
'An instance of HasTextData with a defined _nodeType '
'should return that value in its nodeType proeprty, but '
'"%s" (%s) was returned instead' % (
actual, type( actual ).__name__
)
)
instance = HasTextDataDerived2()
try:
actual = instance.nodeType
expected = HasTextDataDerived._nodeType
self.fail( 'An instance of HasTextData that does not have '
'a _nodeType class-propery defined should raise an '
'AttributeError if nodeType is retrieved' )
except AttributeError:
passclass HasTextDataDerived( HasTextData ):
_nodeName = '#hasTextDataDerived'
_nodeType = 1024
def __init__( self, textData=None ):
HasTextData.__init__( self, textData )
def _SanitizeInput( self, value ):
if value[ 0:12 ] != '[Sanitized] ':
return '[Sanitized] %s' % value
else:
return value
def __str__( self ):
pass
def __unicode__( self ):
pass
def toString( self ):
pass
class HasTextDataDerived2( HasTextData ):
def __init__( self, textData=None ):
HasTextData.__init__( self, textData )
def _SanitizeInput( self, value ):
if value[ 0:12 ] != '[Sanitized] ':
return '[Sanitized] %s' % value
else:
return value
def __str__( self ):
pass
def __unicode__( self ):
pass
def toString( self ):
passFinally, the toString methods. In JavaScript, toString returns a decription of the node rather than its content:
comment = document.createComment( 'comment-node' );
text = document.createTextNode( 'text-node' );
comment.toString();
text.toString();"[object Comment]" "[object Text]"That strikes me as being directly equivalent to the built-in
__repr()__ method, which returns something looking like this:
<[module].[class-name] object at [hex-number]>I'll use that, then. Since all that will do is return the
__repr__()
results for the instance, I see no reason not to just skip the unit-test for it.
The actual implementation of HasTextData.toString is dead simple:
@describe.AttachDocumentation()
@describe.returns( 'A string description of the instance' )
def toString( self ):
"""
Returns a description of the instance"""
return self.__repr__()I hadn't expected to do all the shuffling of functionality into HasTextData
that I've done and show, so this is getting long, but I really want to
get the concrete classes that derive from it finished before I call it a day.
Fortunately, all that movement of functionality doesn't leave much to implement
in them: All that they really need is implementation of _SanitizeInput,
__str__ and __unicode__.
Final Implementation of CDATA
The main purposes that the remaining required methods of CDATA
serve are to ensure that the data, when sent to a client browser,
won't be broken (_SanitizeInput) and to provide rendered output of
the instance, allowing for normal string-values and unicode values both
(__str__ and __unicode__). None of these are
particularly difficult operations:
@describe.AttachDocumentation()
@describe.argument( 'value',
'the text-value to sanitize',
str, unicode
)
@describe.raises( ValueError,
'if a value is passed that cannot be sanitized by the '
'instance to make rendering safely viable'
)
@describe.returns( 'A sanitized str or unicode value' )
def _SanitizeInput( self, value ):
"""
Sanitizes the provided input-value to make sure it's safe to store and issue
to a client browser"""
if ']]>' in value:
raise TypeError( '%s cannot contain "]]>" as a literal value '
'in its text-content.' % ( self.__class__.__name__ ) )
return value
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a str' )
def __str__( self ):
"""
Renders the instance as a string value"""
return '<![CDATA[ %s ]]>' % ( self.data )
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a unicode' )
def __unicode__( self ):
"""
Renders the instance as a unicode value"""
return u'<![CDATA[ %s ]]>' % ( self.data )Of the three, _SanitizeInput probably requires the most
explanation. If it were to allow data values that contained
then it would be possible for a ]]>CDATA
to render as something like
— and that would cause rending issues in the client
browser that the rendered <![CDATA[ This is my CDATA content.]]>
]]>CDATA was handed off to.
While there is provision through the __unicode__ method for unicode
content-output, I may still need to work out some sort of mechanism or
process that will allow a __str__ call to call an instance's
__unicode__ instead, if there is reason for doing so. I suspect
that will involve checking for various unicode errors (UnicodeDecodeError
and UnicodeEncodeError, perhaps?), but I'm not sure yet how that's
going to work, or even if it'll be necessary.
Final Implementation of Comment
The same three methods in Comment look very much like their
counterparts in CDATA, and for much the same reasons:
@describe.AttachDocumentation()
@describe.argument( 'value',
'the text-value to sanitize',
str, unicode
)
@describe.raises( ValueError,
'if a value is passed that cannot be sanitized by the '
'instance to make rendering safely viable'
)
@describe.returns( 'A sanitized str or unicode value' )
def _SanitizeInput( self, value ):
"""
Sanitizes the provided input-value to make sure it's safe to store and issue
to a client browser"""
if '-->' in value:
raise TypeError( '%s cannot contain "-->" as a literal value '
'in its text-content.' % ( self.__class__.__name__ ) )
return value
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a str' )
def __str__( self ):
"""
Renders the instance as a string value"""
return '<!-- %s -->' % ( self.data )
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a unicode' )
def __unicode__( self ):
"""
Renders the instance as a unicode value"""
return u'<!-- %s -->' % ( self.data )Final Implementation of Text
The only consideration for sanitizing the data of a Text
is to make sure that it isn't going to accidentally include any tag-items
in its rendered output. Ensuring that is a sinple mater of escaping any <
characters during the process of setting its data. Technically, that
should be all that's required, since browsers are usually pretty good
about just rendering >
characters if they aren't part of a detectable
tag-structure, but in the interests of making sure that tag-delimiter characters
are all escaped, I'm going to escape both < and >.
@describe.AttachDocumentation()
@describe.argument( 'value',
'the text-value to sanitize',
str, unicode
)
@describe.raises( ValueError,
'if a value is passed that cannot be sanitized by the '
'instance to make rendering safely viable'
)
@describe.returns( 'A sanitized str or unicode value' )
def _SanitizeInput( self, value ):
"""
Sanitizes the provided input-value to make sure it's safe to store and issue
to a client browser"""
sanitized = value.replace( '<', '<' )
sanitized = sanitized.replace( '>', '>' )
return sanitized
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a str' )
def __str__( self ):
"""
Renders the instance as a string value"""
return str( self.data )
@describe.AttachDocumentation()
@describe.returns( 'The instance rendered as a unicode' )
def __unicode__( self ):
"""
Renders the instance as a unicode value"""
return unicode( self.data )That gets me just under 50% of the way done with the markup
module's classes:

idic package,
but since I didn't show all of the code for the work done today, it
seems fair to set up downloads of the current markup.py and
test_markup.py files before I sign off for the day: